限流是什么?
限流,也称流量控制。是指系统在面临高并发,或者 大流量请求 的情况下,限制新的请求对系统的访问 ,从而 保证系统的稳定性 。限流会导致部分用户请求处理不及时或者被拒,这就影响了用户体验。所以一般需要在系统稳定和用户体验之间 平衡 一下。
这里列举一个生活化的例子:
一些热门的旅游景区,一般会对每日的旅游参观人数有限制。每天只会卖出固定数目的门票,比如 5000 张。假设在五一、国庆假期,你去晚了,可能当天的票就已经卖完了,就无法进去游玩了。即使你进去了,排队也能排到你怀疑人生。
为什么需要限流?
限流 (Rate Limiting) 是一种重要的系统保护机制,其主要目的是 控制进入系统或服务的请求流量,以防止系统过载、保证服务稳定性和可用性 。
之所以要使用限流,是因为其具有几大优势:
防止系统过载 :任何系统 (服务器、数据库、网络带宽等) 的处理能力都是有限的。当瞬时流量 (如秒杀、热点事件、恶意攻击) 远超系统承载能力时,可能导致CPU、内存、I/O 等资源耗尽。保证服务质量 :通过限制总请求数或特定用户的请求频率,可以避免少数 “坏邻居” (如恶意爬虫、配置错误的客户端) 占用过多资源,从而保证大多数用户的良好体验和系统响应延迟。抵御DDoS/DoS攻击 :分布式拒绝服务 (DDoS) 或拒绝服务 (DoS) 攻击会通过海量请求淹没目标系统。限流是第一道防线,可以识别并阻止异常的流量洪峰。防止暴力破解 :对登录、支付、验证码等敏感接口进行限流,可以有效防止攻击者通过暴力尝试 (如密码爆破) 来窃取信息或进行欺诈。成本控制 :在云环境中,资源使用通常与成本挂钩 (如按调用次数计费的 API、按流量计费的带宽)。限流可以防止因异常流量导致的成本意外飙升。应对突发流量 :互联网业务常有流量高峰 (如节假日促销、新品发布) 。合理的限流策略 (结合弹性扩容) 可以在系统能力范围内优雅地处理这些峰值,而不是直接崩溃。
四大服务限流算法
常见的限流算法主要有四种:
固定窗口算法
固定窗口其实就是时间窗口,其原理是 将时间划分为固定大小的窗口 ,在每个窗口内限制请求的数量或速率,即固定窗口算法规定了系统单位时间处理的请求数量。
假如我们规定系统中某个接口 1 秒钟只能被访问 3 次的话,使用固定窗口算法的实现思路如下:
将时间划分固定大小窗口,这里是 1s 一个窗口。
给定一个变量 counter 来记录当前接口处理的请求数量,初始值为 0,代表接口当前 1s 内还未处理请求。
1s 之内每处理一个请求之后就将 counter + 1 ,当 counter = 3 之后,也就是在 1s 内接口已经被访问 3 次的话,后续的请求就会被全部拒绝。
等到 1s 结束后,将 counter 重置为 0,重新开始计数。
固定窗口算法的伪代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 @Component public class FixedWindowRateLimiter { private static final long WINDOW_SIZE_MS = 1000 ; private static final int MAX_REQUESTS = 3 ; private final ConcurrentHashMap<String, WindowCounter> counterMap = new ConcurrentHashMap <>(); public boolean isAllowed (String key) { if (key == null || key.trim().isEmpty()) { throw new IllegalArgumentException ("Key cannot be null or empty" ); } long currentTimeMs = System.currentTimeMillis(); long currentWindowStart = getWindowStart(currentTimeMs); return counterMap.compute(key, (k, counter) -> { if (counter == null ) { return new WindowCounter (1 , currentWindowStart); } if (counter.windowStart == currentWindowStart) { if (counter.count < MAX_REQUESTS) { counter.count++; return counter; } else { return counter; } } else { return new WindowCounter (1 , currentWindowStart); } }).count <= MAX_REQUESTS; } private long getWindowStart (long timestamp) { return (timestamp / WINDOW_SIZE_MS) * WINDOW_SIZE_MS; } @Data private static class WindowCounter { int count; long windowStart; public WindowCounter (int count, long windowStart) { this .count = count; this .windowStart = windowStart; } } public WindowCounter getStatus (String key) { return counterMap.get(key); } public void removeKey (String key) { counterMap.remove(key); } }
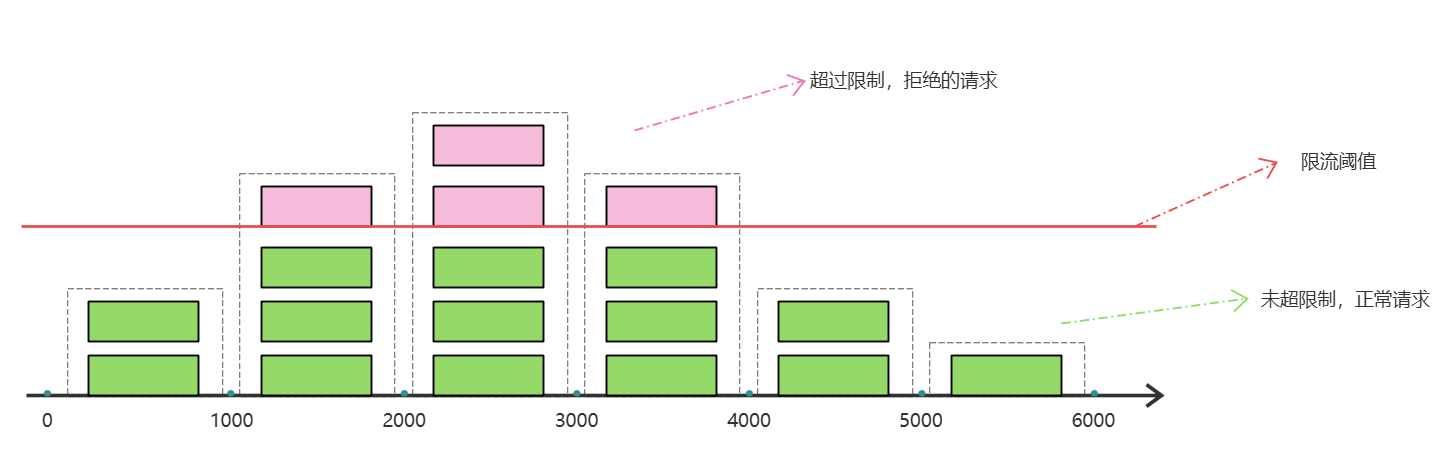
这种算法有一个很明显的 临界问题 :
假如在第 5、6 秒,请求数量都为 3,没有超过阈值,全部放行
但是,如果第 5 秒的三次请求都是在 4.5 ~ 5 秒之间进来;第 6 秒的请求是在 5 ~ 5.5 之间进来。那么从第 4.5 ~ 5.5 之间就有 6 次请求!也就是说每秒的 QPS 达到了 6,远超阈值。
在当前场景下,这 6 个请求在 1s 内是没办法被处理的,系统直接就被瞬时的大量请求给击垮了。
这就是固定窗口算法的问题,它只能统计当前某 1 个时间窗的请求数量是否到达阈值,无法结合前后的时间窗的数据做综合统计。因此,我们就需要 滑动窗口算法 来解决。
滑动窗口算法
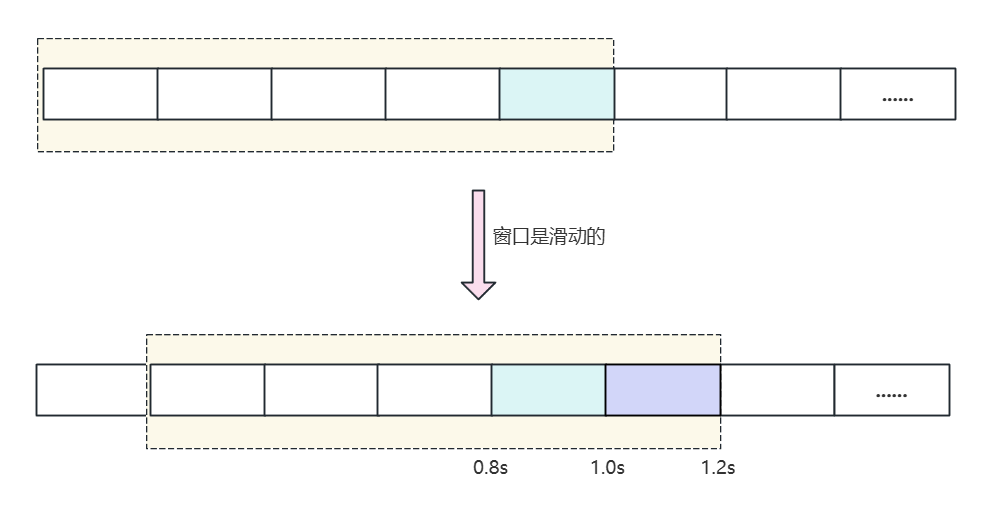
滑动窗口算法算的上是固定窗口算法的升级版,限流的颗粒度更小。滑动窗口算法相比于固定窗口算法的优化在于:它将单位时间周期分为 n 个小周期,分别记录每个小周期内接口的访问次数,并且根据时间滑动删除过期的小周期。 。
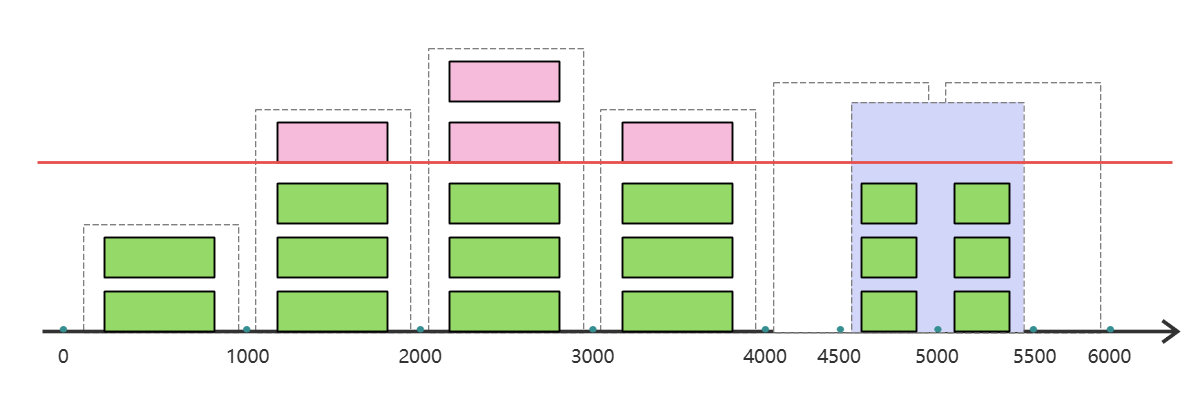
假设单位时间还是 1s,滑动窗口算法把它划分为 5 个小周期,也就是滑动窗口 (单位时间) 被划分为5个小格子。每格表示 0.2s。每过 0.2s,时间窗口就会往右滑动一格。然后每个小周期都有自己独立的计数器,如果请求是 0.83s 到达的,0.8 ~ 1.0s 对应的计数器就会加 1。
假设我们 1s 内的限流阀值是 5 个请求,0.8 ~ 1.0s 内,比如 0.9s 的时候来了 5 个请求,落在天蓝色格子里。时间过了 1.0s 这个点之后,又来 5 个请求,落在紫色格子里。此时如果 是固定窗口算法,是不会被限流的 ,但是 滑动窗口的话,每过一个小周期,它会右移一个小格 。过了 1.0s 这个点后,会右移一小格,当前的单位时间段是 0.2 ~1.2s,这个区域的请求已经超过限定的 5 了,已经触发了限流。实际上,紫色格子的请求就都被拒绝了。
当滑动窗口的格子周期划分的越多,那么滑动窗口的滚动就越平滑,限流的统计就会越精确。
滑动窗口算法的伪代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 @Component public class SlidingWindowBucketRateLimiter { private static final long UNIT_TIME_MS = 1000 ; private static final int NUM_BUCKETS = 5 ; private static final long BUCKET_SIZE_MS = UNIT_TIME_MS / NUM_BUCKETS; private static final int MAX_REQUESTS_PER_UNIT_TIME = 5 ; private final ConcurrentHashMap<String, Bucket[]> bucketMap = new ConcurrentHashMap <>(); public boolean isAllowed (String key) { if (key == null || key.trim().isEmpty()) { throw new IllegalArgumentException ("Key cannot be null or empty" ); } long currentTimeMs = System.currentTimeMillis(); long currentBucketIndex = getCurrentBucketIndex(currentTimeMs); Bucket[] buckets = bucketMap.computeIfAbsent(key, k -> createEmptyBuckets()); long windowStartTimeMs = currentTimeMs - UNIT_TIME_MS; int totalRequestsInWindow = 0 ; for (int i = 0 ; i < NUM_BUCKETS; i++) { Bucket bucket = buckets[i]; if (bucket.timestamp >= windowStartTimeMs) { totalRequestsInWindow += bucket.count.get(); } } if (totalRequestsInWindow >= MAX_REQUESTS_PER_UNIT_TIME) { return false ; } Bucket currentBucket = buckets[(int ) currentBucketIndex]; if (currentBucket.timestamp < currentTimeMs) { synchronized (currentBucket) { if (currentBucket.timestamp < currentTimeMs) { currentBucket.timestamp = getBucketStartTime(currentTimeMs); currentBucket.count.set(1 ); } else { currentBucket.count.incrementAndGet(); } } } else { currentBucket.count.incrementAndGet(); } return true ; } private Bucket[] createEmptyBuckets() { Bucket[] buckets = new Bucket [NUM_BUCKETS]; long currentTimeMs = System.currentTimeMillis(); long baseTime = getBucketStartTime(currentTimeMs); for (int i = 0 ; i < NUM_BUCKETS; i++) { buckets[i] = new Bucket (baseTime + i * BUCKET_SIZE_MS, new AtomicLong (0 )); } return buckets; } private long getCurrentBucketIndex (long timestamp) { long bucketCycle = timestamp / BUCKET_SIZE_MS; return bucketCycle % NUM_BUCKETS; } private long getBucketStartTime (long timestamp) { return (timestamp / BUCKET_SIZE_MS) * BUCKET_SIZE_MS; } @Data private static class Bucket { volatile long timestamp; AtomicLong count; public Bucket (long timestamp, AtomicLong count) { this .timestamp = timestamp; this .count = count; } } private void cleanupStaleKeys () { ... } }
相比于固定窗口算法,滑动窗口算法可以应对突然激增的流量,但还是存在限流不够平滑的问题,且实现和理解起来也更复杂。
例如,我们限制某个接口每分钟只能访问 30 次,假设前 30 秒就有 30 个请求到达的话,那后续 30 秒将无法处理请求,这是不可取的,用户体验极差!
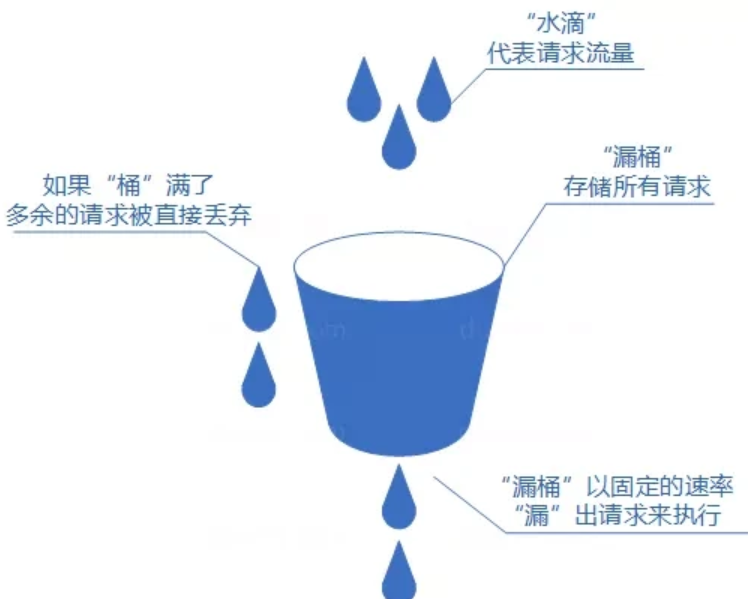
漏桶算法
我们可以把发请求的动作比作成注水到桶中,我们处理请求的过程可以比喻为漏桶漏水。我们往桶中以任意速率流入水,以一定速率流出水。当水超过桶流量则丢弃,因为桶容量是不变的,保证了整体的速率。
如果想要实现这个算法的话也很简单,准备一个队列用来保存请求,然后我们定期从队列中拿请求来执行就好了,和消息队列削峰/限流的思想是一样的。
漏桶算法伪代码实现:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 @Component public class LeakyBucketRateLimiter { private static final long LEAK_RATE_MS = 200 ; private static final int BUCKET_CAPACITY = 10 ; private final ConcurrentHashMap<String, LeakyBucket> bucketMap = new ConcurrentHashMap <>(); public boolean tryAcquire (String key) { if (key == null || key.trim().isEmpty()) { throw new IllegalArgumentException ("Key cannot be null or empty" ); } LeakyBucket bucket = bucketMap.computeIfAbsent(key, k -> new LeakyBucket ()); return bucket.tryAddRequest(); } private static class LeakyBucket { private final AtomicLong waterLevel = new AtomicLong (0 ); private volatile long lastLeakTimestamp = System.currentTimeMillis(); private final ReentrantLock lock = new ReentrantLock (); public boolean tryAddRequest () { long currentTimeMs = System.currentTimeMillis(); leakWater(currentTimeMs); long currentLevel = waterLevel.get(); if (currentLevel < BUCKET_CAPACITY) { if (waterLevel.compareAndSet(currentLevel, currentLevel + 1 )) { return true ; } } return false ; } private void leakWater (long currentTimeMs) { lock.lock(); try { long timeElapsedMs = currentTimeMs - lastLeakTimestamp; if (timeElapsedMs >= LEAK_RATE_MS) { long dropsToLeak = timeElapsedMs / LEAK_RATE_MS; long waterToLeak = Math.min(dropsToLeak, waterLevel.get()); waterLevel.addAndGet(-waterToLeak); lastLeakTimestamp += dropsToLeak * LEAK_RATE_MS; } } finally { lock.unlock(); } } public long getCurrentWaterLevel () { return waterLevel.get(); } public long getLastLeakTimestamp () { return lastLeakTimestamp; } } }
如果桶流入水 (发请求) 的速率如果一直大于桶流出水 (处理请求) 的速率的话,那么桶会一直是满的,一部分新的请求会被丢弃,导致服务质量下降。且漏桶算法无法应对突然激增的流量,因为只能以固定的速率处理请求,对系统资源利用不够友好。
所以实际业务场景中,基本不会使用漏桶算法。
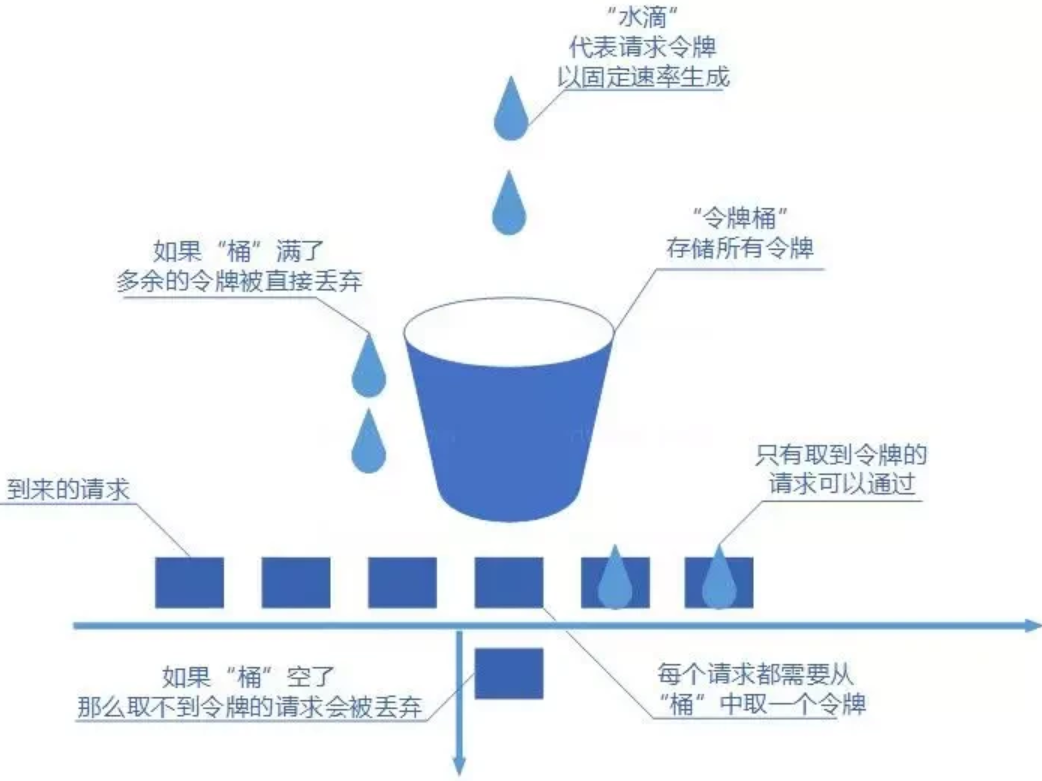
令牌桶算法
令牌桶算法也比较简单和漏桶算法算法一样,都是基于桶的。不过现在桶里装的是令牌了,请求在被处理之前需要拿到一个令牌,请求处理完毕之后将这个令牌丢弃 (删除)。我们根据限流大小,按照一定的速率往桶里添加令牌。如果桶装满了,就不能继续往里面继续添加令牌了。
该算法可以限制平均速率和应对突然激增的流量,也可以动态调整生成令牌的速率。这也是我们最常用的限流算法,因此我们可以使用一些已经封装好的 API 去实现令牌桶限流,这个后续再说。
针对什么进行限流?
实际项目中,还需要确定限流对象,也就是针对什么来进行限流。常见的限流对象如下:
IP:针对 IP 进行限流,适用面较广,简单粗暴。
业务 ID:挑选唯一的业务 ID 以实现更针对性地限流。例如,基于用户 ID 进行限流。
个性化:根据用户的属性或行为,进行不同的限流策略。例如,VIP 用户不限流,而普通用户限流。根据系统的运行指标 (如 QPS、并发调用数、系统负载等),动态调整限流策略。例如,当系统负载较高的时候,控制每秒通过的请求减少。
针对 IP 进行限流是目前比较常用的一个方案。不过,实际应用中需要注意用户真实 IP 地址的正确获取。常用的真实 IP 获取方法有 X-Forwarded-For 和 TCP Options 字段承载真实源 IP 信息。虽然 X-Forwarded-For 字段可能会被伪造,但因为其实现简单方便,很多项目还是直接用的这种方法。
除了上面介绍到的限流对象之外,还有一些其他较为复杂的限流对象策略,比如阿里的 Sentinel 还支持 基于调用关系的限流 (包括基于调用方限流、基于调用链入口限流、关联流量限流等) 以及更细维度的 热点参数限流 (实时的统计热点参数并针对热点参数的资源调用进行流量控制)。
另外,一个项目可以根据具体的业务需求选择多种不同的限流对象搭配使用。
单机限流
基本介绍
单机限流针对的是单体架构应用,可以直接使用 Google Guava 自带的限流工具类 RateLimiter 。 RateLimiter 基于令牌桶算法,可以应对突发流量。
Google Guava 地址:https://github.com/google/guava
除了最基本的令牌桶算法 (平滑突发限流) 实现之外,Guava 的 RateLimiter 还提供了 平滑预热限流 的算法实现。
平滑突发限流就是按照指定的速率放令牌到桶里,而平滑预热限流会有一段预热时间,预热时间之内,速率会逐渐提升到配置的速率。举例说明就是,假设我规定了 1s 处理 10 个请求,那么平滑突发限流就会按照每 0.1s 的速率来生成一个令牌;如果我指定了预热时间,假设指定了预热时间为 3s,那么前 3s 生成令牌的速率不是固定的,而是逐渐提升到 0.1s 生成一个令牌,预热时间 3s 过后才会维持速率统一。
简单使用说明
首先我们需要现在项目中引入 guava 的依赖:
1 2 3 4 5 6 <dependency > <groupId > com.google.guava</groupId > <artifactId > guava</artifactId > <version > 33.4.8-jre</version > </dependency >
平滑突发限流与平滑预热限流调用的 API 是一样的,只是传入的参数数量不一致而已,下面简单进行说明。
1 2 3 4 5 RateLimiter rateLimiter = RateLimiter.create(10.0 );RateLimiter rateLimiter = RateLimiter.create(10.0 , 3 , TimeUnit.SECONDS);
下面是 create() 方法的方法签名,有多个重载:
1 2 3 4 5 public static RateLimiter create (double permitsPerSecond) {...}public static RateLimiter create (double permitsPerSecond, Duration warmupPeriod) {...}public static RateLimiter create (double permitsPerSecond, long warmupPeriod, TimeUnit unit) {...}
下面我们再来介绍一下用于获取令牌的两个方法:acquire() 与 tryAcquire() ,只有获取到令牌的线程才能够处理请求,这是令牌桶的原理。
先来看 acquire() 方法:每次处理一个请求之前,调用 rateLimiter.acquire() 方法来尝试获取令牌。如果没有获得令牌,程序会被阻塞,直到获取到令牌为止。
acquire() 的多个重载方法如下:
1 2 3 4 5 6 7 public double acquire () { return acquire(1 ); } public double acquire (int permits ) {...}
再来看 tryAcquire() 方法:如果不希望阻塞线程,可以使用 tryAcquire() 方法。它会尝试获取令牌,并返回一个布尔值表示是否成功。
tryAcquire() 的多个重载方法如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 public boolean tryAcquire () { return tryAcquire(1 , 0 , MICROSECONDS); } public boolean tryAcquire (Duration timeout) {...}public boolean tryAcquire (long timeout, TimeUnit unit) {...}public boolean tryAcquire (int permits ) { return tryAcquire(permits , 0 , MICROSECONDS); } public boolean tryAcquire (int permits , Duration timeout) {...}public boolean tryAcquire (int permits , long timeout, TimeUnit unit) {...}
方法各个参数的意义一看就明白了,这里不做过多解释。
下面就简单写两个示例代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 public static void main (String[] args) { RateLimiter rateLimiter = RateLimiter.create(10.0 , 3 , TimeUnit.SECONDS); boolean result = rateLimiter.tryAcquire(); if (result) { System.out.println("处理业务 ..." ); } else { System.out.println("拒绝处理业务 ..." ); } }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 public static void main (String[] args) { RateLimiter rateLimiter = RateLimiter.create(10.0 , 3 , TimeUnit.SECONDS); while (true ) { try { if (rateLimiter.tryAcquire(5 )) { System.out.println("处理业务 ..." ); } else { System.out.println("拒绝处理业务 ..." ); } } catch (Exception e) { throw new BusinessException (ErrorCodeEnum.TOO_MANY_REQUEST); } } }
RateLimiter 是线程安全的。
分布式限流
基本介绍
分布式限流针对的分布式/微服务应用架构应用,在这种架构下,单机限流就不适用了,因为会存在多种服务,并且一种服务也可能会被部署多份。
分布式限流常见的方案:
借助中间件限流 :可以借助 Sentinel 或者使用 Redis 来自己实现对应的限流逻辑。网关层限流 :比较常用的一种方案,直接在网关层把限流给安排上。不过,通常网关层限流通常也需要借助到中间件/框架。就比如 Spring Cloud Gateway 的分布式限流实现 RedisRateLimiter 就是基于 Redis + Lua 来实现的,再比如 Spring Cloud Gateway 还可以整合 Sentinel 来做限流。
我们可以使用 Redis + Lua 脚本的形式实现分布式限流。如果不想自己写 Lua 脚本的话,也可以直接利用 Redisson 中的 RRateLimiter 来实现分布式限流,其底层实现就是基于 Lua 代码 + 令牌桶算法。
基于 Redisson 实现分布式限流
引入 Redisson 依赖并配置客户端
引入 Redisson 依赖
1 2 3 4 5 6 <dependency > <groupId > org.redisson</groupId > <artifactId > redisson</artifactId > <version > 3.45.1</version > </dependency >
配置 Redisson 的客户端
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 @Configuration @ConfigurationProperties(prefix = "spring.redis") @Data public class RedissonConfig { private String host; private Integer port; private String password; @Bean public RedissonClient redissonClient () { Config config = new Config (); config.useSingleServer() .setAddress("redis://" + host + ":" + port) .setPassword(password) .setDatabase(1 ); return Redisson.create(config); } }
这里我是选择基于 @ConfigurationProperties 注解去读取配置文件来动态获取 Redis 相关的连接数据
1 2 3 4 5 6 7 spring: redis: host: 192.168 .100 .128 port: 6379 password: 123456 timeout: 10000 database: 0
Redisson 是基于 Netty 实现的,不直接依赖于 Redis,因此无需额外引入 Redis 的依赖。
使用 Docker 开启 Redis,并配置好 Redis 连接信息即可。
实现 Redisson 限流
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 @Component @Slf4j public class RedisLimiterManager { @Resource public RedissonClient redissonClient; public void doRateLimit (String key) { RRateLimiter rRateLimiter = redissonClient.getRateLimiter(key); rRateLimiter.trySetRate(RateType.OVERALL, 2 , Duration.ofSeconds(1 )); boolean result = rRateLimiter.tryAcquire(1 ); if (!result) { log.info("获取令牌失败" ); throw new BusinessException (ErrorCodeEnum.TOO_MANY_REQUEST); } } }
下面进行一些说明:
需要传入一个参数作为标识, 比如 userId , IP 等唯一性的字符串, 这里我选择作为方法参数传入, 由调用方指定
1 public RRateLimiter getRateLimiter (String name) {...}
1 2 3 boolean trySetRate (RateType mode, long rate, Duration rateInterval) {...}boolean trySetRate (RateType mode, long rate, Duration rateInterval, Duration keepAliveTime) {...}
第一个参数是表示限流方式,有两个模式可以选择:
1 2 3 4 5 6 7 8 9 10 11 12 public enum RateType { OVERALL, PER_CLIENT }
第二个参数与第三个参数一起看,一个是速率,一个是速率的时间间隔,比如 2, Duration.ofSeconds(1) 就表示 1s 处理两个请求;又比如 300, Duration.ofHours(1) 表示 1 小时处理 300 个请求。
第四个参数可选,表示限流器删除之前等待的时间,规定时间内如果桶中还没有令牌的话,限流器就会被删除。
Redisson 还提供了 trySetRateAsync() ,用于异步的设置。
获取令牌的方法与 Guava 类似,还是通过 acquire() 与 tryAcquire() 方法,只不过这两个方法都是同步方法。
Redisson 也提供了对应的异步方法来进行获取:acquireAsync() 与 tryAcquireAsync() 。
我们只需要在 ServiceImpl 中注入定义的限流 Bean,然后在需要限流的方法中调用即可。
简单示例:
1 2 3 4 5 6 7 final String IDENTIFICATION = loginUser.getId();redisLimiterManager.doRateLimit(IDENTIFICATION);
本篇博客借鉴于 JavaGuide ,并在此基础上添加个人的理解。
 QQ
QQ 微信
微信 支付宝
支付宝


