如何保证缓存与数据库的一致性
想要解决缓存与数据库的一致性问题,需要先了解常见的缓存更新策略。
常见的缓存更新策略
旁路缓存
旁路缓存就是 Cache Aside,也是我们平时业务中经常使用的一种方式。
旁路缓存读取数据的基本流程是:先从 Redis 缓存中读取数据,数据存在则直接返回,数据不存在则需要数据库中去读取,然后再写入缓存。
旁路缓存写入就比较麻烦了:先写入缓存还是先写数据库、写入缓存还是删除缓存、怎么保证缓存与数据库的一致性 ……,这个有点麻烦,我们后续再说。
总结起来,旁路缓存这种方式的特点就是业务代码既要操作数据库又要操作缓存,以数据库的数据为主,缓存只是暂时存储数据而已。这就是我们经常使用的旁路缓存 Cache Aside。
读穿写穿
读穿 Read Through、写穿 Write Through,这是第二种常见的缓存更新策略。它的设计思想是:不直接操作数据库,只操作缓存,让缓存自身去操作数据库。
读穿的意思是,每次都从缓存中进行读取。如果缓存中存在,则直接返回;如果缓存中不存在数据,则让 缓存自身 去数据库中进行查询,然后写入到缓存当中,返回数据。
写穿的意思是,每次写入数据,直接写入到缓存当中,后续 缓存自身 再写入数据到数据库当中。
总结起来,读穿写穿就是让我们直接操作缓存,只与缓存进行交互,读写数据库的操作交由缓存中间件自身完成。
写回
第三种缓存更新策略是写回 Write Back。写回与读穿写穿的思路是一致的,都是直接操作缓存,读写数据库的操作交由缓存中间件自身完成,但是区别是:写回是异步的写入数据到数据库。
也就是说,写回操作只写入数据到缓存,然后让后台线程异步的把缓存的更新写入数据库。这种非常适合写多读少的场景,但是因为是异步地写数据库,所以如果突然宕机, 会有数据丢失的可能。
思想的应用
无论是读穿写穿,还是写回,目前做业务的缓存,像 Redis 或者 Memcached, 又或者大厂自研的缓存中间件都没提供这种缓存自身和数据库交互的功能,但是这种思想其实大量的应用到了操作系统和一些中间件的底层设计。
比如 MySQL 的 Buffer Pool。Buffer Pool 就是 MySQL 在内存中的 一个缓冲池。MySQL 插入数据都是先写入 Buffer Pool,然后在某个时间异步的刷到磁盘当中。然后 MySQL 通过 redolog 来避免数据丢失。
再比如操作系统的内核缓冲区 Page Cache,其本质也是一个缓存。也是先把数据写入到 Page Cache,然后操作系统在某个时间把数据刷入到磁盘当中。
其实一些典型的应用场景也使用了这种思想。比如 IDEA 编辑器、画图的软件或者写简历的在线网站,你不去点保存,它也会在某个时间自动地保存数据到磁盘或云端当中,这就是写回思想的一种应用。
怎么保存缓存和数据库的数据一致性?
现在我们回头再来看最常用的旁路缓存的写入策略,看看这种更新策略是如何保存缓存和数据库的数据一致性。
先更新缓存,再更新数据库
假设有如下的场景:
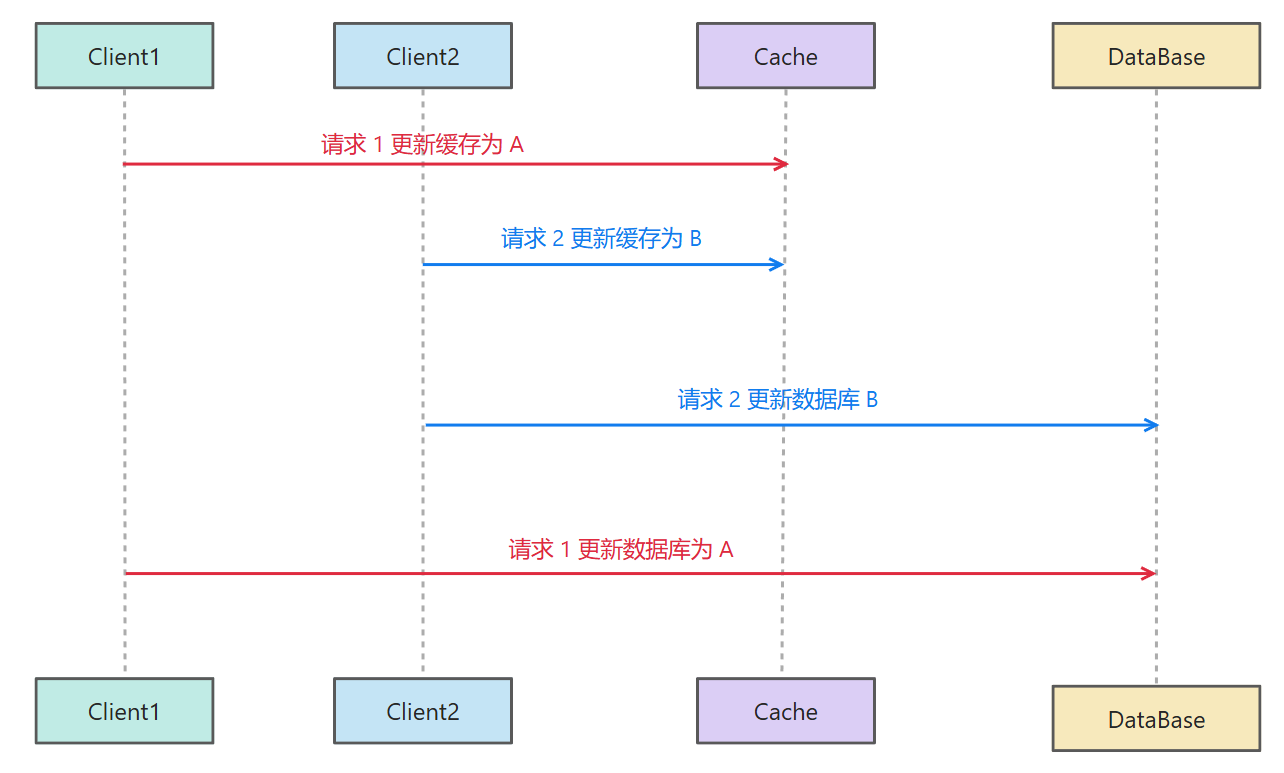
这样就会出现缓存和数据库的不一致性。
先更新数据库,再更新缓存
那我们反过来换一个思路:先更新数据库,再更新缓存。假设存在如下的场景:
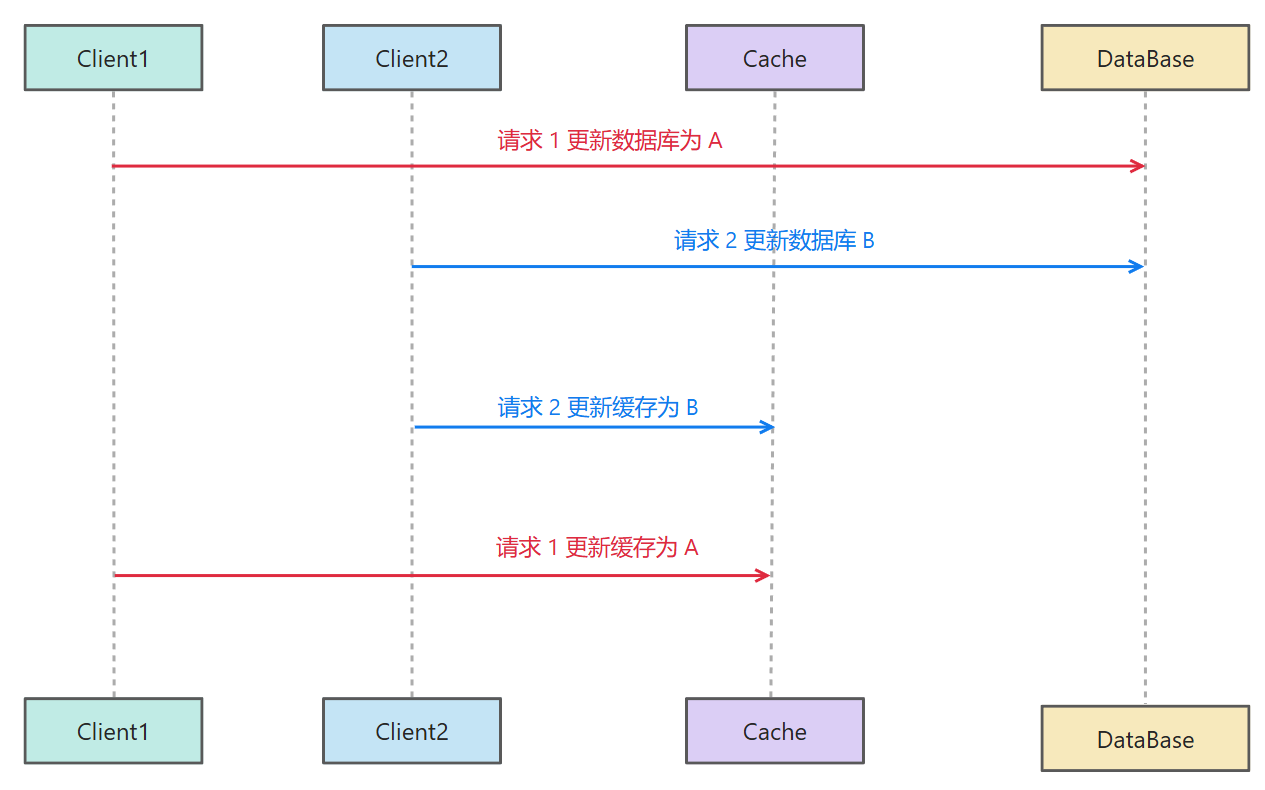
此时又出现了缓存和数据库的不一致性。
一起来看前两种方案,出现缓存和数据库的不一致性的原因主要是:缓存的更新与数据库的更新不是一个原子性的操作,在并发环境下就可能会出现不一致的问题。
那是不是只要保证缓存的更新与数据库的更新是一个原子性操作就能保证缓存和数据库的一致性?
此时我们会想到:分布式锁 。只要保证拿到锁的线程才能更新缓存,更新数据库,这不就保证原子性操作了吗,就能保证缓存和数据库的一致性了吗?
然而事实真是如此吗?
首先我们来分析,如果加了分布式锁,就不能并发写了,写操作一旦过多,还会导致性能问题。其次分布式锁本身也存在一些难以解决的问题,因此 使用分布式锁的方式不能够保证缓存和数据库的一致性。
那选择使用分布式读写锁,利用其读读不互斥,读写互斥的特性?
其实这种方案还不如第一种分布式锁的方案。首先读写锁是读写互斥的,读的时候不允许写;写的时候不允许读,这样就会导致如下的问题:
在高并发场景下,大量的请求进来都在读取这个 key,此时你完全不能进行写操作;
如果此时你正在执行一个比较耗时的写操作,突然涌入大量的读取操作,那么这些大量的请求就只能阻塞等待写操作完成后在执行
再退一步来说,我们为什么选择使用缓存?首先想到的就是 **Redis 是基于内存操作,读写速率非常快!**但现在我们为了数据的一致性而选择了加锁这种比较重的资源,反而影响了 Redis 的读写性能,是不是本末倒置了,忘记了我们使用缓存的初衷?
综合来说,无论是先更新缓存还是先更新数据库,这两种方案是都不能保证缓存和数据库的一致性的。
先删除缓存,再更新数据库
既然更新缓存行不通,那我们就再换个思路:删除缓存。这里选择删除缓存是因为以下两点原因:
- 删除缓存操作相比于更新缓存代价更低,操作更便捷
- 如果更新了缓存没有请求去访问,然后数据库又进行了更新,那就意味着还需要重新更新缓存,那之前更新的缓存不就是无效的,没有意义的?
所以对于缓存来说,最好的方案就是:需要查询的时候再去更新;更新数据库的时候直接删除缓存即可。
现在确定了策略就是先删除缓存,再更新数据库,此时还会不会出现缓存和数据库的不一致问题呢?
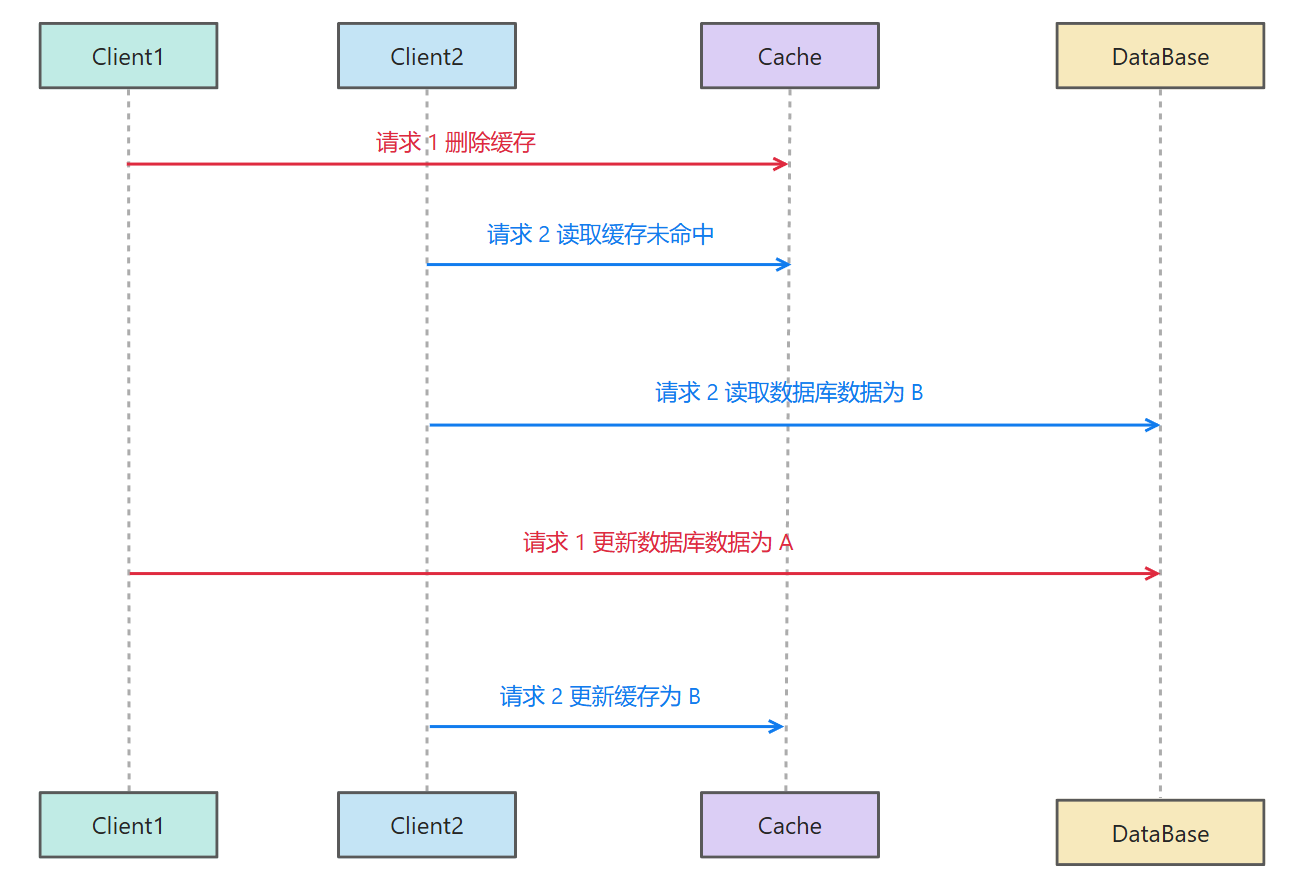
可以看到,此时又又又出现了缓存和数据库的不一致性。
延迟双删
既然有其他的请求会更新缓存,导致数据的不一致,那么可不可以把最后一次更新缓存的数据给删除了,这样不就能保证数据的一致性了吗?
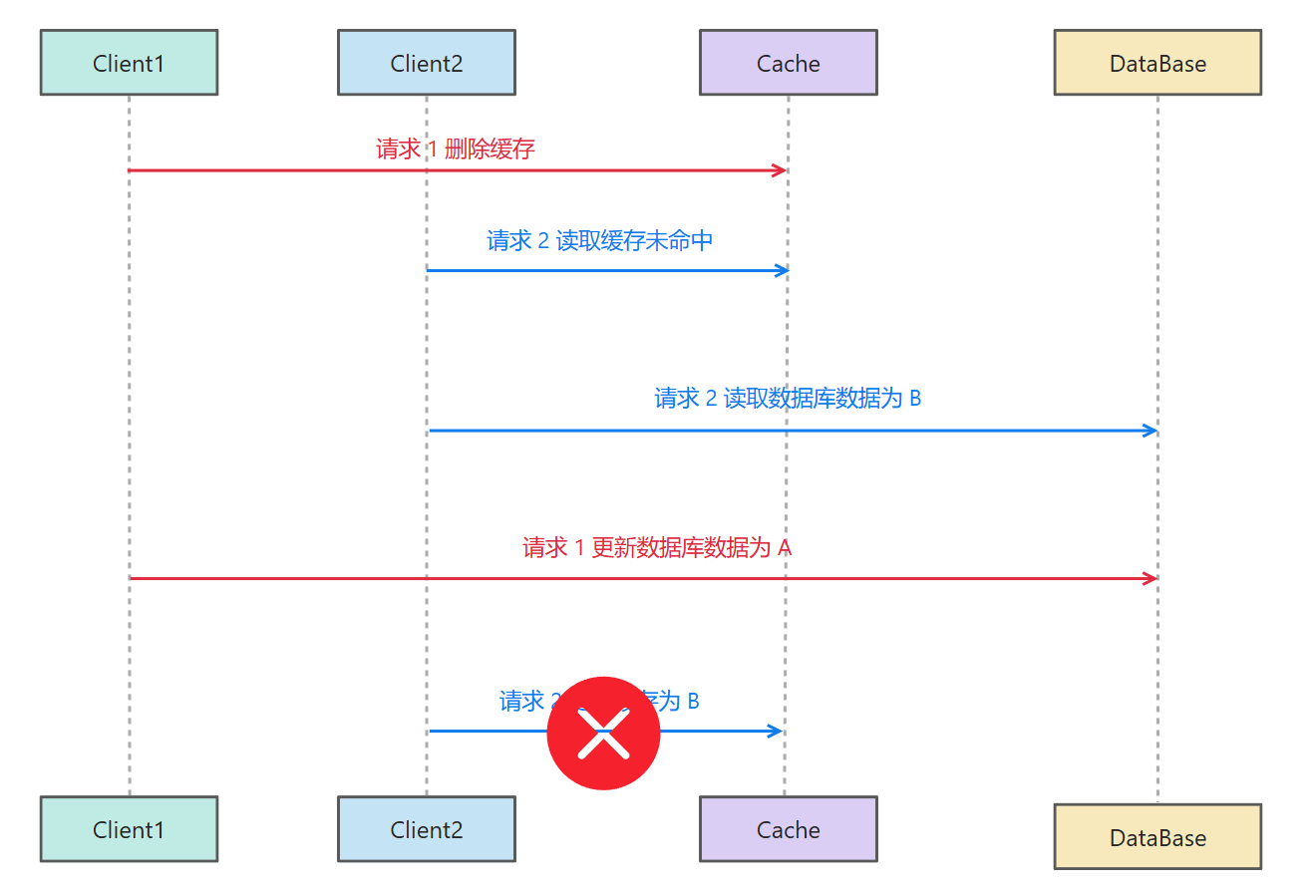
具体的操作就是:先删除缓存,再更新数据库,然后让线程等待一会再去执行删除最后更新的缓存。这里线程等待的原因就是留出时间给其他的线程进行读取数据库数据并写入缓存的操作,然后再把写入缓存的数据一删,这样就保证了缓存与数据库的一致性,这多是一件美事!🤪🤪🤪
然而事实就是这样吗?这里还存在一个不确定性的因素:延迟双删,那么线程应该等待多久呢,到底需要多长时间其他线程能完成进行读取数据库数据并写入缓存的操作呢?
这不仅需要考虑当时的网络情况,还跟服务器与数据库的负载相关,这个时间是不确定的,没有一个准确的值。因此延迟双删这个方案也是不可行的。
先更新数据库,再删除缓存
那我思路再变,先更新数据库,再删除缓存。
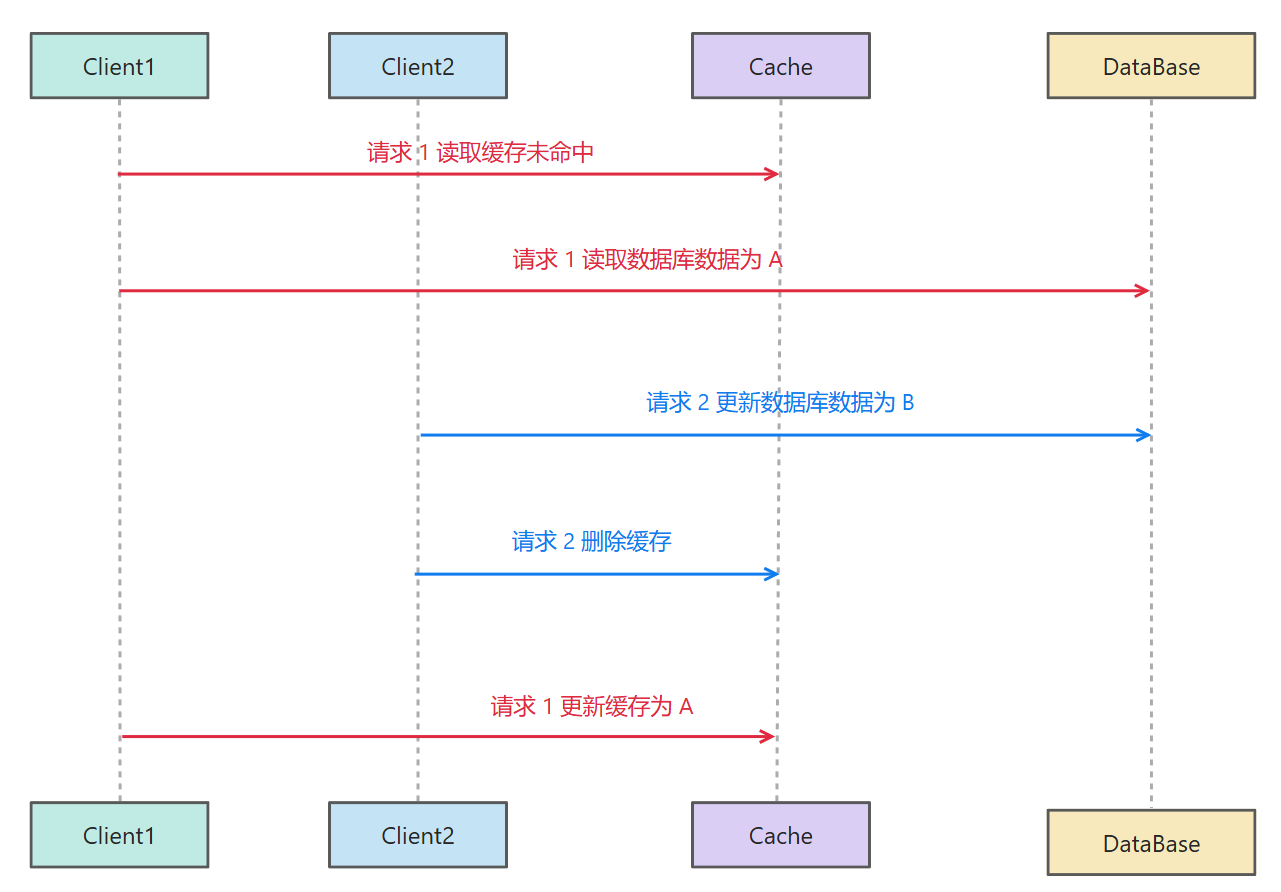
但是此时又又又又又出现了缓存与数据库数据的不一致问题!!!
不过这种方案出现缓存与数据库数据的不一致性是概率很低的。需要同时满足以下两点原因才有可能出现不一致性:
- Key 正好过期且数据库也需要更新数据
- 请求 1 写缓存的速度 要小于 请求 2 更新数据库数据加删除缓存的概率 ,这是概率极其低的
由此来说:先更新数据库,再删除缓存,这种方案在绝大多数情况下是可行的。
如果数据库更新成功,缓存删除失败了呢?
这种情况下就又又又出现了缓存与数据库数据的不一致问题,所以我们的解决思路应该是:必须要确保删除缓存的操作要成功执行。
为了保证成功执行,我们主要有两个方案:使用 MQ 或 监听 binlog 日志。
方案一
把删除缓存的操作放入到 MQ 中去异步的执行,如果删除失败了,就可以利用 MQ 的重试机制进行重试,这样就能够有效保证删除缓存操作的执行。
方案二
数据库更新数据的时候会产生一个 binlog 日志,我们也可以通过监听 MySQL 的 binlog 日志,如果日志中出现了数据,就代表 MySQL 进行了更新操作。我们再执行相应的删除缓存操作,删除失败再进行重试即可。
所以综合看下来,最理想的方案就是:先更新数据库,然后通过 MQ 或 监听 binlog 的方式异步删除缓存,如果删除缓存失败就进行重试。
主从模式下的不一致性问题
实际上企业或公司的数据库都是主从模式读写分离的,主库负责写操作,从库负责读取,主库更新数据之后再同步给从库。
此时就会出现一个问题:主库执行数据更新操作并删除缓存之后,还没来得及同步给从库,此时又来了请求读取该数据,从库负责读,那么势必会读取从库的旧数据,然后写入缓存,这就又造成了缓存和数据库数据的不一致性,当然这种概率也是非常非常非常低的。
而想要解决这个问题,那就需要在主库更新数据后的一段时间内让后续的请求强制读取主库。
总结
此时到这里我们就应该明白:想要完全的保证缓存与数据库数据的一致性,那是不可能的。
我们最常用的方式就是:先更新数据库,然后通过 MQ 或 监听 binlog 的方式异步删除缓存,如果删除缓存失败就进行重试。 这也只是尽可能地保证缓存和数据库的在绝大多数场景下的一致性,同时我们也需要设置好数据的过期时间,即使某些极端场景下出现了不一致性问题,那也能够及时保证脏数据的过期失效。
 QQ
QQ 微信
微信 支付宝
支付宝




