MySQL 中 SQL 的执行流程与编写顺序
一条 SQL 语句是如何执行的?
先说结论:一条 SQL 语句的执行需要经历:连接器、缓存层、解析器、优化器、执行器 五个步骤。下面以一个买鸡蛋的例子来进行说明 SQL 的具体执行流程。
连接器
首先买鸡蛋的第一步就是:让妈妈先找到我,给我一个去买鸡蛋的指令。
相应的,我们需要执行 SQL,第一步就是先连接上数据库,通过网络把 SQL 语句传输过去,然后数据库才能帮我执行 SQL 语句。
这就是连接器的工作,连接器就是客户端与数据库之间进行连接,主要步骤是:
- 先进行 TCP 的三次握手与数据库建立连接
- 校验客户端的用户名与密码是否正确,不正确则报错
- 做权限校验,判断当前用户是否有权限访问数据库
缓存层
现在我收到了买鸡蛋的指令,下一步就直接出门去买吗?当然不是!我们应该先看看家里还有没有剩下的鸡蛋,有就直接用呗,没有了才去买。
相应的,连接上数据库之后,需要先查询缓存。以传输的 SQL 语句作为 key,以查询的结果作为 value,如果缓存中存在 value,那就说明之前执行过一样的SQL 语句,那我就直接拿来用呗,不用重复执行了。
为什么 MySQL 会有缓存存在?
程序有时间局部性,当某一段代码或者某一段指令被执行时,很有可能这段代码还会被重复执行。或者说某一段内存位置被访问时,很有可能这个内存位置还会被再次访问,这是因为代码中会存在大量的循环、递归等操作,导致某段指令被重复执行,这就是时间局部性的原理。所以一条被执行过的 SQL,在未来很有可能被再次执行,这就是为啥要对 SQL 做缓存。
为什么 MySQL 8.0 又去掉了缓存?
因为一旦表数据一变化,那 SQL 执行的结果就有可能不一样,所以表数据变化时就应该删除缓存。而实际上很多 SQL 在执行的时候,where 条件是会不断变化的,这就导致了 SQL 看着都差不多,但是条件稍微不一样它就走不了缓存,所以查询缓存的命中率并不高,MySQL 在 8.0 就把查询缓存去掉了。
解析层
回到买鸡蛋的问题,现在家里确定没有鸡蛋了,要去买。但是还需要思考一个问题:我想要吃鸡蛋吗?我不想吃就要告诉我妈妈不买了,我想吃就要考虑买多少个。
相应的,SQL 语句下一步到达解析器。解析器就是判断 SQL 语句的具体想法,分为三步:
词法分析。拆分 SQL 语句的关键词,比如
select、from、where、order by等。语法分析。判断 SQL 语句的编写语法是否是正确的,不正确就报错;正确的话就构建语法解析树,方便后续获得表名、字段名。
检查表,判断字段是否存在。
优化器
现在我确定要买鸡蛋,我确实想吃鸡蛋,我也确定了要买 20 个鸡蛋。接下来就需要计划怎么买了:是去超市买还是去菜市场买?是骑车去买还是坐公交车去买?
相应的,SQL 语句接下来就到了优化器。优化器的职责就是给 SQL 制定一个计划:怎么执行 SQL 是最快的,是走索引还是全表扫描,走索引的话走哪个索引?
执行器
现在我的计划完成了,然后就是执行计划:骑车去菜市场买鸡蛋。所以我就还需要跟卖鸡蛋的老板交流,付钱。
相应的,SQL 语句最后抵达执行器。执行器的任务就是与存储引擎层进行交互,执行相应的 SQL 语句,然后从存储引擎中拿到结果返回。
总结
一条 SQL 语句的执行顺序可以以下图作为参考: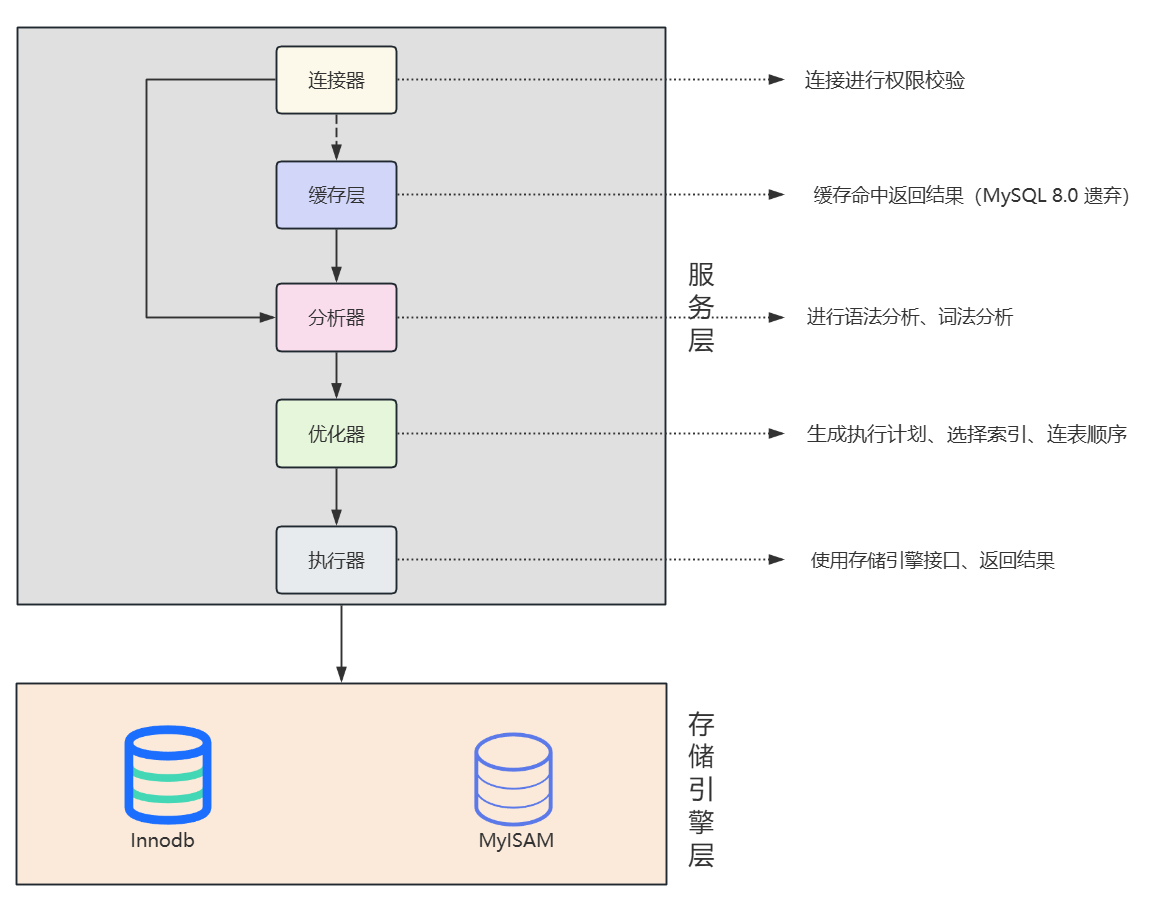
SQL 语句顺序
SQL 编写顺序
1 | select 字段名 |
SQL 执行顺序
1 | from 表名 |
 QQ
QQ 微信
微信 支付宝
支付宝




